Update
Note
This is an advanced topic for administrators. The update command is used in special situations to convert some old data to newer formats. Most likely, you do not need it.
Sometimes, with new, more efficient ways of storing and retrieving information, updates are necessary to the data already existing in the database. After the introduction of such improved methods, PersephoneShell is updated and the new versions start loading the data using the new formats. The Persephone client will keep working with the data in the older formats, but we highly recommend converting the stored data to the new form. In most cases, this will result in considerable space and transfer time savings. Please review each sub-command.
Usage:
update <target> <path> [-v] [-t | -f] [-o]
Targets:
quantitative, storage, synteny, ribbons, data_version, gc_content
update quantitative
The data for quantitative tracks is stored in a binary form. We introduced pre-calculated low resolution data that help rapid displaying of the quantitative tracks. To calculate such binary histograms from the older data blocks, run the command update quantitative. As usual, test it first using the switch -t (it will show how many tracks will be updated and simulate the conversion without writing anything into the database). If needed, PersephoneShell will also add the new column to the database:
PS> update quantitative -t
The column QUANT_RUN_PAIR.lowres_data does not exist in the database. Creating...
Column QUANT_RUN_PAIR.lowres_data has been added
Selected 24 BedGraph tracks
Do you want to test-update 24 tracks? (Y/N) Y
Processing 24 BedGraph tracks:
Load track Methylation, Map "Chr.1", MapSet "Human GRCh37.p13", id 253796972
Count of all blocks=1048 ...
Loading blocks from 0 to 500, Done, compressed size 0.05MB.
Parsing:
500/500 Done 0 sec.
Loading blocks from 500 to 1000, Done, compressed size 0.05MB.
Parsing:
500/500 Done 0 sec.
Loading blocks from 1000 to 1048, Done, compressed size 0.00MB.
Parsing:
48/48 Done 0 sec.
Store index data for track trackId=253796972, size:19818 Done 1 sec.
Track id 253796972 processed, 5 sec.
Load track Methylation, Map "Chr.2", MapSet "Human GRCh37.p13", id 253796973
Count of all blocks=697 ...
You can interrupt the test and execute the actual conversion (usually, with the verbose mode flag -v):
PS> update quantitative -v
It is also possible to update the data for just one map set specified by map set path (below) or by the numeric MapSetId:
PS> update quantitative "Human/Human GRCh37.p13" -v
update storage
The genomic sequences can be stored in the database (Oracle only), Amazon's S3 or the file system. Before 2020, each sequence stored in the file system resulted in two files on disk, which means that for a map set of one million scaffolds, you would need 2 million files - not optimal! The new approach introduced in 2020 has changed the way the sequences are stored: small sequences are bundled together and this dramatically reduces the number of files with the sequence data.
The transition from the old files to the new ones is done by the command update storage:
Test the procedure first:
PS> update storage -t
1 'Filesystem' storage found:
Id: 1 Path: /data/seq/windseq
Storage Id to test? 1
There are 49,267 old sequences
Tested 1,120, 2.27%, 64.99 sequences/sec, ETA: 13.8 min
...
The real update of the sequences is done like the following (usually, with the verbose mode flag -v):
PS> update storage -v
1 'Filesystem' storage found:
Id: 1 Path: /data/seq/windseq
Storage Id to update? 1
There are 49,267 old sequences
Re-compressed 1,320, 2.68%, 54.48 sequences/sec, ETA: 25.8 min
...
Note
To migrate the sequences from Oracle database to the files, you will need another tool. Please contact Persephone Software.
update synteny (update ribbons)
Around summer of 2020, we introduced a better way of storing and displaying the synteny ribbons. With the new approach, the synteny ribbons are "anchored" to a specialized track of type SYNTENY_TRACK (it was ANNOT_TRACK with gene models before). The brick-like visual elements shown in the synteny tracks represent the regions to which the ribbons are attached. Normally, the ribbon elements connect the sequence intervals with high similarity. If a region has many ribbons attached, that would appear as a "pile of bricks", this would indicate that this region is highly conserved. A click on such "brick" element will align the corresponding region of the syntenic map.
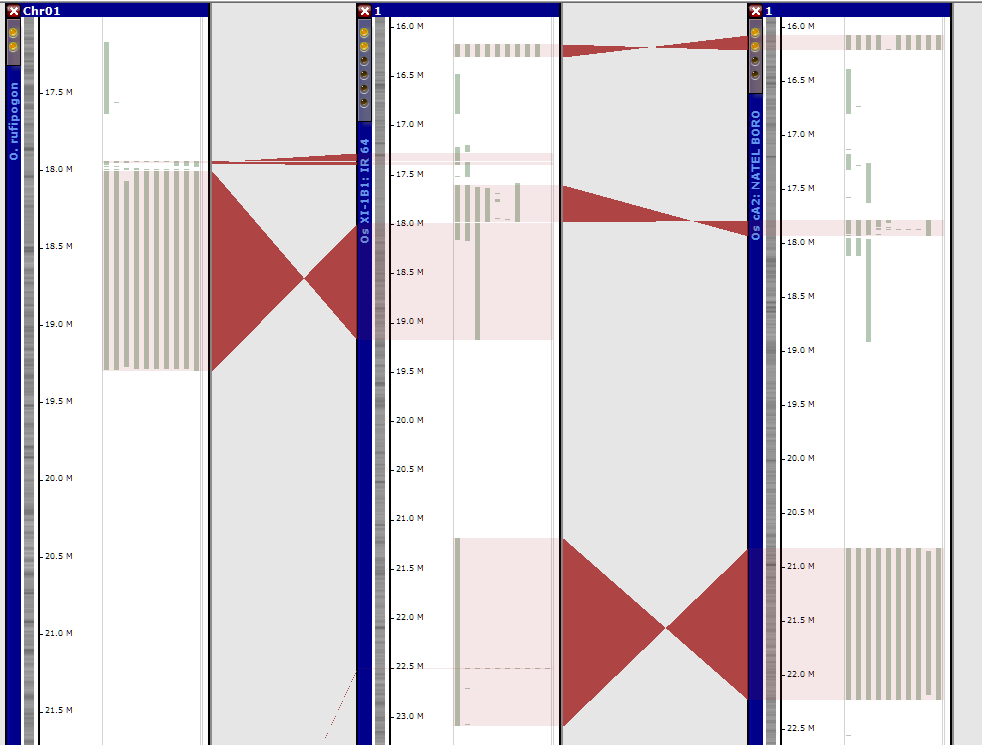
Conservation tracks with the brick-like ribbon anchors show the inversions (rice pan-genome)
If you have records stored in the database before summer 2020, you will need to update the records using the command update synteny, which will add the conservation tracks:
PS> update synteny -t
- 20 empty tracks used to anchor the ribbons will be converted from ANNOT_TRACK to SYNTENY_TRACK type
- For 5 annotation tracks used to anchor the ribbons, additional synteny tracks will be created
If all looks as expected, run the actual update:
PS> update synteny -v
- 20 empty annotation tracks converted to type SYNTENY_TRACK
- 5 tracks have been added to be used as the anchors for ribbons
- 1940 TRACK_CONNECTOR records updated
update data_version
Every data change in the database should trigger the cache reset in the client applications. This is done by updating the values in the table DATA_VERSION. PersephoneShell does it automatically for each data manipulation, such as adding a track or editing the map set description. Still, if you modify the data using direct SQL queries outside PersephoneShell, you need to update the records in DATA_VERSION. Note, maintaining the correct data version Is mostly important for the Web version of Persephone that actively uses browser's and the server's cache. Updating the data version will force the cache to be reset. The Windows version will engage the cache only if explicitly instructed via the configuration settings (TrackCacheSettings), so if using cache is set to false, the command update data_version will have no effect on the Windows version.
update gc_content
The version of Persephone introduced in the end of 2020 shows statistics of the sequences. The map set properties form has a new tab that, besides other values, shows the number of undefined nucleotides (Ns) in the entire genome. Calculating this number is a time-consuming task that, without the gc_content update, will be performed in the run time. In case of thousands of sequences in the selected map set, the calculation can take quite a while. The command update gc_content re-analyzes each sequence, generates a new GC histogram and stores the total number of Ns into the database for quick retrieval.
Test the data first using the switch -t:
PS> update gc_content -t
Updating GC histograms for all 68 map sets listed in the tree, in Test Mode
Updating 1/68 map set: '/Brachypodium/Brachypodium distachyon Bd21' (id:200081226)
Creating GC histogram for 5 sequences, in Test Mode
Done, processed 5 sequences
Map set does not have the count of Ns saved in db, requires updating
Updating 2/68 map set: '/Glycine max/Glycine max Wm82.a1.v1 (id:200207306)
Creating GC histogram for 20 sequences, in Test Mode
Done, processed 20 sequences
Map set does not have the count of Ns saved in db, requires updating...
The actual gc_content conversion can be done for the entire database or for a selected map set:
PS> update gc_content "Medicago sativa/CADL" -v
Do you want to update GC histograms for map set '/Medicago sativa/CADL' (id:262880824)? (Y/N) Y
Updating 1/1 map set: '/Medicago sativa/CADL' (id:262880824)
Creating GC histogram for 6593 sequences
Done, processed 6593 sequences
update track_qualifier
This command creates a new table TRACK_QUALIFIER needed for webPersephone's Edit tracks interface.
PS> update track_qualifier
 Copyright © 2009-2024 by Persephone Software. All Rights Reserved.
Copyright © 2009-2024 by Persephone Software. All Rights Reserved.